Reverb is one of the most interesting aspects of digital signal processing effects for audio. It is a form of processing that is well-suited to digital processing, while being completely impractical with analog electronics. Because of this, digital signal processing has had a profound affect on our ability to place elements of our music into different “spaces.”
Before digital processing, reverb was created by using transducers—a speaker and a microphone, essentially—at two ends of a physical delay element. That delay element was typically a set of metal springs, a suspended metal plate, or an actual room.The physical delay element offered little variation in the control of the reverb sound. And these reverb “spaces” weren’t very portable; spring reverb was the only practically portable—and generally affordable—option, but they were the least acceptable in terms of sound.
First a quick look at what reverb is: Natural reverberation is the result of sound reflecting off surfaces in a confined space. Sound emanates from its source at 1100 feet per second, and strikes wall surfaces, reflecting off them at various angles. Some of these reflections meet your ears immediately (“early reflections”), while others continue to bounce off other surfaces until meeting your ears. Hard and massive surfaces—concrete walls, for instance—reflect the sound with modest attenuation, while softer surfaces absorb much of the sound, especially the high frequency components. The combination of room size, complexity and angle of the walls and room contents, and the density of the surfaces dictate the room’s “sound.”
In the digital domain, raw delay time is limited only by available memory, and the number of reflections and simulation of frequency-dependent effects (filtering) are limited only by processing speed.
Two possible approaches to simulating reverb
Let’s look at two possible approaches to simulating reverb digitally. First, the brute-force approach:
Reverb is a time-invariant effect. This means that it doesn’t matter when you play a note—you’ll still get the same resulting reverberation. (Contrast this to a time-variant effect such as flanging, where the output sound depends on the note’s relationship to the flanging sweep.)
Time-invariant systems can be completely characterized by their impulse response. Have you ever gone into a large empty room—a gym or hall—and listened to its characteristic sound? You probably made a short sound—a single handclap works great—then listened as the reverberation tapered off. If so, you were listening to the room’s impulse response.
The impulse response tells everything about the room. That single handclap tells you immediately how intense the reverberation is and how long it takes to dies out, and whether the room sounds “good.” Not only is it easy for your ears to categorize the room based on the impulse response, but we can perform sophisticated signal analysis on a recording of the resulting reverberation as well. Indeed, the impulse response tells all.
The reason this works is that an impulse is, in its ideal form, an instantaneous sound that carries equal energy at all frequencies. What comes back, in the form of reverberation, is the room’s response to that instantaneous, all-frequency burst.
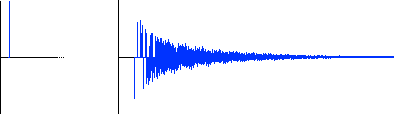
An impulse and its response
In the real world, the handclap—or a popping balloon, an exploding firecracker, or the snap of an electric arc—serves as the impulse. If you digitize the resulting room response and look at it in a sound-editing program, it looks like decaying noise. After some density build-up at the beginning, it decays smoothly toward zero. In fact, smoother sounding rooms show a smoother decay.
In the digital domain, it’s easy to realize that each sample point of the response can be viewed as a discrete echo of the impulse. Since, ideally, the impulse is a single non-zero sample, it’s not a stretch to realize that a series of samples—a sound played in the room—would be the sum of the responses of each individual sample at their respective times (this is called superposition).
In other words, if we have a digitized impulse response, we can easily add that exact room characteristic to any digitized dry sound. Multiplying each point of the impulse response by the amplitude of a sample yields the room’s response to that sample; we simply do that for each sample of the sound that we want to “place” into that room. This yields a bunch—as many as we have samples—of overlapping responses that we simply add together.
Easy. But extremely expensive computationally. Each sample of the input is multiplied individually by each sample of the impulse response, and added to the mix. If we have n samples to process, and the impulse response is m samples long, we need to perform n×m multiplications and additions. So, if the impulse response is three seconds (a big room), and we need to process one minute of music, we need to do about 350 trillion multiplications and the same number of additions (assuming a 44.1KHz sampling rate).
This may be acceptable if you want to let your computer crunch the numbers for a day before you can hear the result, but it’s clearly not usable for real-time effects. Too bad, because its promising in several aspects. In particular, you can accurately mimic any room in the world if you have its impulse response, and you can easily generate your own artificial impulse responses to invent your own “rooms” (for instance, a simple decaying noise sequence gives a smooth reverb, though one with much personality).
Actually, there’s a way to handle this more practically. We’ve been talking about time-domain processing here, and the process of multiplying the two sampled signals is called “convolution.” While convolution in the time domain requires many operations, the equivalent in the frequency domain requires drastically reduced computation (convolution in the time domain is equivalent to multiplication in the frequency domain). I won’t elaborate here, but you can check out Bill Gardner’s article, “Efficient Convolution Without Input/Output Delay” for a promising approach. (I haven’t tried his technique, but I hope to give it a shot when I have time.)
A practical approach to digital reverb
The digital reverbs we all know and love take a different approach. Basically, they use multiple delays and feedback to built up a dense series of echoes that dies out over time. The functional building blocks are well known; it’s variations and how they are stacked together that give an digital reverb units its characteristic sound.
The simplest approach would be a single delay with part of the signal fed back into the delay, creating a repeating echo that fades out (the feedback gain must be less than 1). Mixing in similar delays of different sizes would increase the echo density and get closer to reverberation. For instance, using different delay lengths based on prime numbers would ensure that each echo fell between other echoes, enhancing density.
In practice, this simple arrangement doesn’t work very well. It takes too many of these hard echoes to make a smooth wall of reverb. Also, the simple feedback is the recipe for a comb filter, resulting in frequency cancellations that can mimic room effects, but can also yield ringing and instability. While useful, these comb filters alone don’t give a satisfying reverb effect.
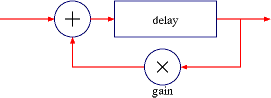
Comb filter reverb element
By feeding forward (inverted) as well as back, we fill in the frequency cancellations, making the system an all-pass filter. All-Pass filters give us the echoes as before, but a smoother frequency response. They have the effect of frequency-dependent delay, smearing the harmonics of the input signal and getting closer to a true reverb sound. Combinations of these comb and all-pass recirculating delays—in series, parallel, and even nested—and other elements, such as filtering in the feedback path to simulate high-frequency absorption, result in the final product.
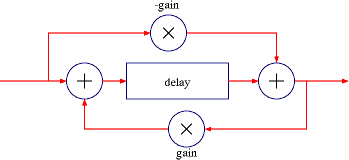
All-Pass filter reverb element
I’ll stop here, because there are many readily available texts on the subject and this is just an introduction. Personally, I found enough information for my own experiments in “Musical Applications of Microprocessors” by Hal Chamberlin, and Bill Gardner’s works on the subject, available here on the web.
Good article. Nice accessible section on convolution reverb.
Your allpass is different than the one at https://ccrma.stanford.edu/~jos/pasp/Allpass_Two_Combs.html
Error?
Hi Sam,
Both are allpass filters—if you do a web search for allpass filters, especially related to reverbs (where block diagrams are often included), you can see other examples of the form I posted. It’s been a long time since that article, so I don’t recall my source, but when I derive it now, the JOS version (with summers on the outside) is the most obvious. However, the version I have here is slightly more efficient to code. I see that Bill Gardner’s work shows the form I have here, so that may have been my source.
BTW, I have a partially written article on convolution on the back burner, waiting for time to put together an interactive demo…
It’s an interesting exercise to code up both flavors of allpass and look at how different their impulse responses are, even though they are both allpass.
They look exactly equal to me, probably you had the sign inverted in one of them?
The link to the book at the bottom is broken.
Yes. Unfortunately, Bill’s work hasn’t been available for several years. You can find his projects page here, but the “list of publications” link is stale there as well. His most interesting paper is Efficient Convolution without Input Output Delay, which describes the basis for convolution reverbs. You should be able to get it through aes.org.
Very good blog! Thank you!
Thanks for wonderful blog, I am in process of reading every post in your archive.
I was wondering if you would please be so kind to send/upload Bill Gardner’s text you are referring to,
1. Bill Gardner’s article, “Efficient Convolution Without Input/Output Delay”
2. “Musical Applications of Microprocessors” by Hal Chamberlin, and Bill Gardner
I am trying to get that ‘gut feeling’ for digital filter (designing), this will be a lot of help.
Please oblige.
Thanks. 🙂
Shashank
PS: I am asking just for ‘self-learning’, no commercial (or whatever they call it) violation is intended.
Hi Shashank,
Musical Application of Microprocessors was first published in 1980 (there was a second edition, subsequently), so it’s not something that exists in pdf or online format.
The Bill Gardner paper…he had it online at one time, then pulled it, apparently, some years ago. However, I believe that there are other more recent papers that probably go into more detail than the original (look for “fast convolution” with variable block sizes)…Actually, I just did a search on “gardner efficient convolution without input/output delay” and the second link was a pdf of Gardner’s original paper.
Nigel
This is a helpful post. Thanks.
Should it read “we need to perform n*m multiplications and additions” (rather than n+m)?
Nice catch after 22 years—thanks!
The link for “Musical Applications of Microprocessors” by Hal Chamberlin, and Bill Gardner will not open for me. It may be my University firewall but unsure.