Certain aspects of the ADSR are up for interpretation. Exactly how the ADSR re-triggers when not starting from idle, for instance. Also, we can decide whether we want constant rate, or constant time control of the segments. The attack segment is fixed in height, so starting from idle (0.0 level) to peak (we’ll use 1.0 in our implementation—feel free to multiply the output to any level you want), there is no difference between constant rate and constant time. But for the decay and release segments, the distance traveled is dependent on the sustain level. I choose constant rate—this means that the release setting is for a time from the maximum envelope value (1.0) to 0.0; if sustain is set mid-way at 0.5, the release will take less time to complete than if it were at 1.0, but the rate of fall will be the same.
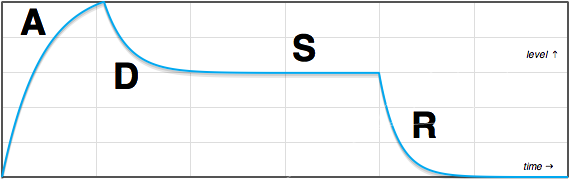
Time
There is one problem about how much time it takes for an exponential move: In theory, it takes forever.
That’s OK for decay and release, since it will become so tiny after a point that there is no difference between the near-zero output and zero. For attack, however, it’s a big issue. We don’t move to the decay state until the attack state hits the maximum at 1.0. If it never hits, we’re in trouble. No problem—we just aim a little higher than 1.0, and when it crosses 1.0 we move to the decay state.
In practice, floating point numbers have limitations and it won’t take forever (depending on the exact math used). But we’d spend way too much time making unnoticeably tiny moves as we get close to 1.0; certainly, we want to clip the exponential attack. Hardware envelope generators do the same thing, hitting a trigger level to switch to the decay state.
But there’s an aesthetic reason to clip the attack exponential as well. There are a number of reasons that the shape of “decaying” upwards towards a maximum value is the wrong shape for a volume envelope. It’s likely that the popular attack curve for hardware generators was a compromise between an acceptable shape and convenience (it’s easy to generate).
Math
While the math of the curve itself is simple due to the nature of generating a exponential curve iteratively (we just feed back a portion), the math of relating rates to coefficients is a bit more work. I decided that instead of arbitrary (“1-10”) control settings for the rates, I wanted to set the segments by time (in samples) for the segment to complete. So, a setting of 100 would make the envelope attack from 0.0 to 1.0 in 100 samples. A setting of 100 for release would hit 0.0 in 100 samples if sustain were set at maximum, 1.0, but sooner if it were set lower—constant rate, not time.
Again, we need only clip the attack segment, since we wouldn’t notice the difference between a full exponential and a slightly clipped one for the decay and release segments. However, putting a cap on those segments has some advantages. One is that we use a little less processing for envelopes in the idle state. But there’s another trick I chose to implement, after experimenting a bit and giving thought to exponential versus linear segments. Read on.
Shape control
One way to handle terminating exponential segments would be to set a threshold that is deemed “close enough”. For instance, as the attack segment gets within, say, 0.001 of 1.0, we simply set the output to 1.0 and move to the decay state. But if we take a slightly different approach, shooting for a target of 1.001 instead, and terminating when it hits or crosses 1.0, then we won’t have a noticeable step if we decide to make that “overshoot” value much larger.
Why would we want to make it much larger? That would wreck our nice exponential. In fact, if we make it too large, the moves would be virtually…linear! So, we could use a small number to stay near-exponential, or move to larger numbers to move towards linear segments, giving us a very versatile ADSR with curve control very simply.
More math
Usually, the rate of an exponential is based on the time it takes to decay to half the current value. But since we’re truncating our exponentials, I chose to define our rate controls as the time it takes to complete our attack from 0.0 to 1.0, or the decay or release to move from 1.0 to 0.0 (which happens for decay when the sustain level is set to 0.0, or release when sustain is 1.0).
Exponential calculations can be relatively CPU intensive. But, fortunately, envelope generators produce their output iteratively. And an iterative implementation of the exponential calculation is a trivial computation. We can calculate the first step of the exponential, whenever the appropriate rate setting is changed, then use it as the multiplier for subsequent iterations (remember the one-pole filter? Simple multiplies and additions).
rate = exp(-log((1 + targetRatio) / targetRatio) / time);
where targetRatio is our “overshoot” value, the constant 1 is because we are moving a distance of 1 (0.0 to 1.0, or 1.0 to 0.0), and time is the number of samples for the move. Typically, we’ll pick a targetRatio that we like (a larger number to approximate linear, or a small fraction to approach exponential); time comes from our rate knob, perhaps via a lookup table so that we can span from 1 sample to five or ten seconds worth of samples in a reasonable manner.
I chose to refer to the overshoot adjustment as a “target ratio” because it’s related to the size of the move, and it’s helpful to think of it in terms of dB, especially related to loudness. For the release to decay to -60 dB, for instance, we use a value of 0.001; -80 dB is 0.0001. Using smaller values will have a significant effect on how “wide” the top of the attack segment is, at a given attack rate setting. To convert from dB to the ratio value, use 10 raised to the power of your dB value divided by 20; in C, “pow(10, val / 20.0)”.
Another pleasant byproduct of using this “target ratio” (overshoot) for all curves is that we don’t need to guard against output decaying into denormals and ruining performance.
Next: Code
Up next is source code. As usual, I try to keep the code simple yet flexible. You may want to add features to auto-retrigger the envelope for repeating patterns, add delay and hold features, or add additional segments—that’s where you distinguish yourself. And this ADSR has features lacking in many implementations already—adjustable curves, and precise specification of attack time in samples, for instance.